
Machine Learning for Beginners: How AI Really Works Behind the Scenes
Estimated read time... 10 - 12 minutes
Updated 12 Mar 2026
What it is:
Machine learning is software that learns from patterns in data instead of following a fixed set of rules.
It is the “brain” inside many AI tools you already use, like the technology that suggests your next Netflix show, flags bank fraud, or fixes your typing.
The catch
Machine learning is like a very fast student with no common sense.
It is excellent at spotting patterns, but it does not truly understand what it is doing and can only predict the most likely next step based on the data it has seen.
The goal
By understanding this, you can stop treating AI as magic and start using it as a predictable tool to handle repetitive, manual data tasks in your work or business.
Right. Before you scroll past this, hear me out for thirty seconds.
You already use machine learning about twenty times a day. Netflix knows you're a "cosy murder mystery" person, not a rom-com person, even if you'd never admit it.
Your bank quietly blocked that suspicious transaction before you even noticed.
Google Maps rerouted you around that accident eight minutes before you'd have hit it.
None of that happened by accident. Someone taught a computer to learn from patterns rather than follow a fixed script.
That's machine learning. And once you understand how it works, a lot of modern technology suddenly makes sense.

This post is part of a series. If you haven't read What is AI? The plain-English guide yet, start there.
It covers the big picture. This post goes one level deeper, into the engine room.
By the end, you'll understand why your spam filter works, why AI tools still make confident mistakes, and why the models powering everything in 2026 are genuinely different from what existed three years ago.
📚 What Is Machine Learning, In Simple Terms?
Machine learning is a way of teaching computers to learn from examples and patterns in data instead of following fixed rules written by humans.

Artificial Intelligence (AI)
The broad category.
AI is any software that does something we'd normally associate with human intelligence: recognising faces, understanding spoken words, making decisions.
It describes what the system does, not how it does it.
Machine Learning (ML)
The method behind most modern AI. And the main subject of this post.
Traditional programming works like a recipe. You give the computer an exact list of instructions. If A happens, do B. If C happens, do D. It follows them precisely and breaks down the moment something unexpected appears.
Machine learning is different.
Instead of writing rules, you show the system thousands of examples and let it find the patterns itself.
Think about teaching a teenager to cook. You don't hand them a 47-step manual covering every scenario. You let them experiment. They learn that turning the heat too high burns everything. They figure it out without you spelling it out each time.
That's machine learning. The system learns from experience rather than instructions.
If any of the terminology here starts to blur together, our AI buzzwords explained: plain English guide is worth bookmarking. It covers the terms you'll keep running into without making you feel like you're reading a textbook.
🧠 Quick fact : Machine learning models can actually "forget" old information when learning new things - it's called "catastrophic forgetting"
Deep Learning
A specific type of machine learning that uses layers of connected calculations (loosely inspired by how the brain is structured) to handle much more complex tasks.
This is what powers GPT-5.2 writing your emails and Claude 4.6 summarising a 40-page contract in under a minute.
We'll cover deep learning properly in the next post in this series. For now, treat it as the advanced, specialist version of what we're discussing here.
Machine learning spots patterns. Deep learning stacks those patterns in layers to handle things far more complex. Same foundation, completely different ceiling.
🧑🏫 What Are The Three Main Types of Machine Learning?
The three main types of machine learning are supervised learning, unsupervised learning, and reinforcement learning and they're about as different as your friends' methods for pulling:
What is Supervised Learning (the Keen Student)?
Supervised learning is a type of machine learning that learns from labelled examples where the correct answer is already known.
This is the most common type. You give the system a large set of examples that already have the correct answers attached.
The system studies the patterns and learns to apply them to new examples it hasn't seen before.

Imagine teaching a computer to spot spam emails. You feed it ten thousand emails, each one already labelled "spam" or "not spam."
It studies the patterns: certain phrases, suspicious sender addresses, that unmistakable tone of someone deeply concerned about your car insurance.
Eventually it starts correctly labelling new emails on its own.
Where you encounter supervised learning:
Email spam filters
Bank fraud detection catching suspicious transactions
Medical image analysis flagging potential disease markers
Autocorrect (the version that works, not the one that changes "duck" into something unfortunate
The strength: accuracy, because it learned from verified correct examples.
The catch: you need a lot of labelled data.
Labelling data is tedious, time-consuming work, and someone has to do it.
Every one of those emails in my junk folder was stopped before it reached my inbox. No rules were written, no one reviewed them manually. The spam filter learned what suspicious looks like from millions of examples and applies that knowledge to every email you receive.
What is Unsupervised Learning (the Nosy Detective)?
Unsupervised learning is a type of machine learning that looks for patterns and groups in data that has no labels or correct answers.
Here you hand the system a pile of data with no labels, no right answers, and no instructions about what to find. It goes full Sherlock Holmes.

This is useful when you don't know what you're looking for yet.
You're not teaching it to recognise a specific thing. You're asking it to surface patterns nobody thought to look for.
A supermarket feeds three years of sales data into an unsupervised system.
Nobody tells it what to find. It comes back and says: "These customers reliably buy nappies and beer together on Friday evenings." Nobody programmed that insight in.
The system found it by identifying clusters in the data.
Where you encounter unsupervised learning:
Customer segmentation (why Amazon seems to know what you want before you do)
Anomaly detection in network security
Market research surfacing trends that weren't on anyone's radar
What is Reinforcement Learning and How Does it Work?
Reinforcement learning is a type of machine learning that learns by trial and error, using rewards and penalties to improve its choices over time.
This one works like a video game. The system tries an action, gets a reward if it went well and a penalty if it didn't, then tries again. It improves through pure, relentless repetition.

Think of how a toddler learns to walk.
Nobody programs the exact muscle movements required. The toddler tries, falls, adjusts, tries again. Over thousands of attempts, the approach that works emerges.
Reinforcement learning runs the same process, but at millions of iterations in hours rather than months.
Where you encounter reinforcement learning:
Video game AI opponents that adapt to your skill level
The systems that taught computers to beat world champions at chess and Go
Self-driving vehicle training
Social media algorithms deciding what to show you next (which is a reminder that the reward signal matters enormously)
🧬 How is a Machine Learning System Built Step by Step?
Building a machine learning system means collecting and cleaning data, training a model, testing it on fresh data, deploying it, and then continuously monitoring and retraining it as the world changes.
This is the part most people skip. That's a mistake, because it explains why AI tools fail in specific, predictable ways.
Step 1: What is Data Collection in ML?
Data collection is the process of gathering enough relevant, high‑quality examples for the model to learn from.
Everything starts here.
Machine learning systems learn from examples, which means you need a lot of them and they need to be good quality.
The rule in this field is blunt: rubbish in, rubbish out.
The most sophisticated algorithm in existence can't learn useful things from poor data. It's like trying to learn French from a phrasebook full of typos.
If you're wondering whether this affects the tools you use day to day, it does.
The quality and diversity of training data is one of the main reasons some AI tools are dramatically better than others at the same task.
Step 2: What is Data Cleaning in ML?
Data cleaning is the process of fixing or removing errors and inconsistencies in your data so the model is learning from accurate information.
Real‑world data is messy: missing values, contradictions, the person who entered their age as “banana.” This step removes the noise before training starts.
Data scientists will tell you this unglamorous step takes up the majority of their time.
They're not exaggerating.

Step 3: What is Model Training in ML?
Model training is the stage where the algorithm learns patterns from data by repeatedly making predictions and adjusting itself based on the errors.
This is where learning actually happens. The system processes the cleaned data, makes predictions, gets corrected, adjusts its internal calculations, and repeats.
It's like learning to throw darts. First attempts go everywhere.
After ten thousand throws, a pattern emerges. After a million throws, which a computer can simulate in hours, accuracy gets genuinely impressive.
The key thing to understand: the model isn't memorising the right answers. It's finding the underlying patterns that produced those answers.
That's what allows it to handle new situations it was never explicitly trained on.
Step 4: What is Testing on Fresh Data in ML
Testing on fresh data checks whether a trained model can generalise its learning to new, unseen examples instead of just memorising the training set.
You test the trained system on examples it has never seen before. This shows you whether the system has learned useful patterns or is only good at repeating what it was shown during training.

This matters because a system can become excellent at memorising its training examples without learning anything transferable. This failure mode is called overfitting.
It's like a student who memorises every past exam paper but falls apart when a question is phrased slightly differently. They haven't learned the subject. They've learned the questions.
Testing on fresh data tells you whether the system has genuinely learned something useful, or just memorised what it was shown.
Step 5: What is Deployment in ML?
Deployment is the stage where a trained machine learning model is integrated into a real product or workflow so it can make live predictions.
The system goes live. It is exciting or terrifying, depending on how thorough steps 1 through 4 were.
Step 6: What is Monitoring and Retraining? (The Part Everyone Underestimates)
Monitoring and retraining is the ongoing process of checking a model’s performance in the real world and updating it with new data so it stays accurate over time.
This is where the common misconception appears. People assume that once a model is trained and deployed, it stays smart.
It doesn't.
The world changes. People's behaviour shifts. Language evolves. A model trained on data from 2022 will start giving increasingly odd responses as the gap between its training data and current reality widens.
This is called data drift. The model isn't broken. Its reference point has just become outdated.

Here's the analogy: imagine a brilliant baker who moves from Manchester to Tokyo. Every skill they have is real. But the ingredients are different. The local preferences are different.
The suppliers stock unfamiliar products.
Their expertise still exists, but they have to relearn how to apply it in the new context. Until they do, some of their output will be confidently wrong in ways that puzzle people who expect them to just know.
That's data drift. The model was trained on yesterday's world. Reality moved on.
This is also why no machine learning system, however sophisticated, replaces ongoing human oversight.
Someone needs to watch for the signs of drift and trigger retraining before the errors compound.
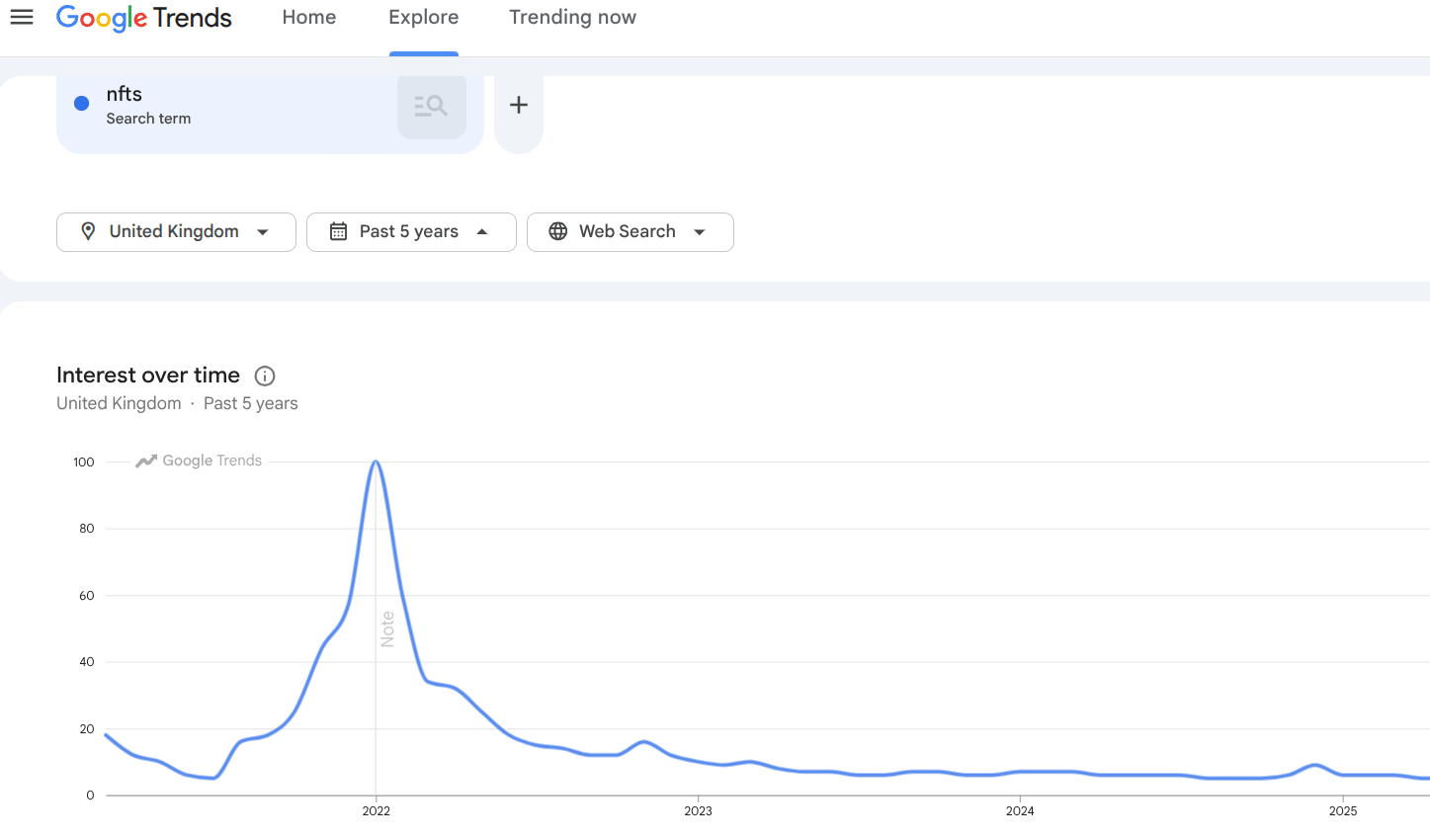
This is what data drift looks like in the real world. The model was trained when this topic was everywhere. By the time the trend fell off, the model's understanding of what was "normal" was already out of date. The expertise was real. The reference point had just moved on.
⚡ What are Foundation Models (the AI Tools you are Already Using)?
Foundation models are large, general-purpose AI systems trained on massive amounts of data so they can handle many different tasks instead of just one.
You have probably heard of ChatGPT, Claude, and Gemini. These are what the field calls foundation models.
The name reflects the idea that they're a base layer.
One model, trained on an enormous volume of text and data, that can write, summarise, answer questions, explain code, draft emails, and do dozens of other tasks reasonably well.
Before foundation models, you needed a separate AI system for each task.
Foundation models collapsed that into a single general-purpose tool.
What makes them different from earlier ML systems:
Trained on vast amounts of data, including a significant portion of publicly available internet text
Capable of handling tasks they weren't explicitly trained on, by applying patterns from related domains
Adaptable for specific uses without being rebuilt from scratch

GPT-5.2 and Claude 4.6 (the standard tools as of March 2026) both now use Search-Augmented Generation, or SAG.
In practical terms: they search the live web while generating a response. They're no longer limited to their training data cutoff.
That's a genuine and meaningful improvement.
It does not mean they're always right.
Both tools still have the Confident Intern problem.
They produce confident-sounding responses regardless of whether they're drawing on solid evidence or filling gaps with plausible-sounding guesswork. SAG gives the intern a smartphone.
It doesn't give them better judgement about which sources to trust, or the instinct to say "I'm not sure about this one."
Always verify anything important. Treat AI output as a well-researched first draft, not a finished fact
If you want to get better results from these tools rather than fighting the Confident Intern, how to write your first AI prompt (even if you're clueless) covers the practical techniques.
Most of the frustration people have with AI tools disappears once they understand how to ask better questions.
For a deeper look at how foundation models work technically, Stanford's Centre for Research on Foundation Models publishes accessible research at crfm.stanford.edu.
It's written for a general audience and worth an hour of your time if you want to go beyond the basics covered here.
🏆 Ready to become an AI-savvy legend? Download our free beginner cheat sheet – it's got everything you need to start using machine learning tools like a pro, without the technical headaches.
📉 What is Machine Learning Good at, and Where Does it Fall Down?
Where Does Machine Learning Work Best?
Machine learning works best when it is spotting patterns in large datasets that would take humans far longer to analyse.
Spotting patterns in large datasets.
A human reviewing ten thousand customer transactions for fraud patterns would take weeks and miss things.
A trained ML system does it in seconds and catches signals too subtle for humans to notice reliably.

Repetitive classification tasks.
Is this spam? Is this a cat? Is this transaction suspicious? Tasks with clear right and wrong answers, applied at high volume.
Generating first drafts.
Not final work. Starting points. The difference between a blank page and something to react to.
Consistency at scale.
ML systems don't have bad days, don't get tired, and don't need motivational talks. For high-volume repeatable tasks, that reliability is genuinely valuable.
Where Does Machine Learning Struggle?
Machine learning struggles with common sense, real-world context, and knowing when it is wrong.
Common sense and context.
ML systems learn patterns from data. They don't have an internal model of how the world works the way humans do.
They can produce a perfectly correct answer to a question and completely miss the obvious follow-up that any person would anticipate.
Knowing when it's wrong.
This is the most practically important limitation. ML systems, especially language models, don't have a reliable mechanism for flagging uncertainty.
The confident tone doesn't change based on whether the model is very sure or completely guessing.

Bias from training data.
If the training data reflects historical biases (and most real-world data does), the system reproduces those biases in its outputs.
This has been demonstrated in hiring tools, facial recognition accuracy across demographic groups, and credit scoring. It's not a theoretical concern.
Genuinely original thinking.
ML systems recombine patterns from their training data. The results can look creative.
But the underlying process is different from the lateral thinking that produces genuinely novel ideas.
If you're curious about where these limitations show up in practice and how to work around them, 5 common AI mistakes that beginners make (and how to fix them fast) covers the ones people hit most often.
💡What Are The Main Ethical Issues With Machine Learning
Machine learning is powerful enough to cause real harm when it goes wrong or is deployed carelessly. These are the concerns worth knowing, not as abstract warnings, but as practical context for using these tools.

How Can Machine Learning Create Bias and Discrimination?
Machine learning systems can reinforce or amplify existing social biases if they are trained on biased data.
Systems trained on biased data make biased decisions. When those decisions affect hiring, lending, or legal outcomes, the consequences for real people are serious.
A recruiting tool trained primarily on historical hiring data from a male-dominated industry will tend to favour male candidates.
It is not intentional. It is a direct reflection of what the training data contained.

What is the Right to Explainability in Machine Learning?
The Right to Explainability is the legal right to a clear explanation when an automated system makes a decision that significantly affects you.
This is new as of 2026 and worth knowing about.
In an increasing number of jurisdictions, people now have a legal right to an explanation when an automated system makes a decision that significantly affects them.
If an ML model rejects your loan application or filters your CV out of a job shortlist, the company using that model must be able to explain why the machine made that choice.
"The AI decided" is no longer a complete answer.
Businesses using ML for consequential decisions need to understand what their systems are actually doing, not just whether they produce acceptable accuracy metrics overall.
This matters for you as someone using AI tools too. It's a good instinct to apply in everyday use: if you can't explain why an AI output is useful, that's a signal to look more closely before acting on it.

What is Privacy in Machine Learning?
Machine learning often relies on large amounts of personal data, so how that data is collected, stored, and used has serious privacy implications.
Before you start pasting client documents, contracts, or sensitive business data into any AI tool, read our AI security guide: what is safe to share.
It covers exactly what is fine, what is risky, and what to avoid, with specific examples for small business owners.
What is Accountability in Machine Learning?
Accountability in machine learning means humans remain responsible for the outcomes of AI systems, especially when those systems make consequential mistakes.
When an ML system makes a consequential mistake, who is responsible?
This is still genuinely unsettled in most industries and legal frameworks. The practical takeaway is that humans remain responsible for decisions made using AI tools. “The model told me to” is not a defence.

🥼 How Can You go Deeper into Machine Learning Without a Computer Science Degree?
If this post has made you curious about the actual mechanics, here are the best resources that don't require a technical background.
Google's Machine Learning Crash Course at developers.google.com/machine-learning/crash-course is free, well-structured, and designed for people without a maths or coding background. It's the most accessible technical introduction available.
Kaggle at kaggle.com runs free beginner courses and provides datasets you can experiment with. If you want to see machine learning in action rather than just reading about it, Kaggle is where most people start.
Both are genuinely worth an afternoon if you want to go further than this post takes you
🥡 Key takeaways about Machine Learning
Machine learning is pattern recognition at scale. It finds structure in data and uses that structure to make predictions or decisions.
Three approaches: supervised (learns from labelled examples), unsupervised (finds patterns without labels), reinforcement (improves through trial, reward, and repetition).
Data quality determines output quality. No algorithm fixes bad data.
Models don't stay smart forever. Data drift is real. Without monitoring and retraining, performance degrades as the world changes.
GPT-5.2 and Claude 4.6 now use SAG to search the live web. That's a genuine improvement. It doesn't eliminate the Confident Intern problem.
The Right to Explainability is now law in many places. If a machine makes a decision that affects you, you can ask why.
Limitations are real and predictable. Understanding them makes you a better user of these tools, not a more sceptical one.
🥳 What Comes Next
This post covered the foundation: what machine learning is, how it gets built, and where it succeeds or falls short.
The next post in this series goes one level deeper.
Deep learning is a specific architecture within machine learning that uses layered networks of calculations to handle tasks that would defeat standard ML approaches.
It's what makes image recognition work, what powers voice assistants, and what's behind the language models you use every day.
Understanding it doesn't require a maths degree. It requires the right analogy.
Deep learning: the AI that knows you better than your mum is the next post in this series. It picks up exactly where this one ends.
📖 Not ready to go deeper yet? The Free Beginner's AI Cheat Sheet has a plain-English glossary of the terms in this post, plus a breakdown of which tools are worth starting with. Keep it open while you explore.

No Jargon AI
Making AI make sense - one prompt at a time
Declaration
Some links on this site are affiliate links.
I may earn a small commission, but it doesn't
cost you anything extra.
I only recommend tools i trust
Thank you for your support
Socials
Location
Based in Mansfield, Nottinghamshire
Simplifying AI for beginners, no matter
where you're starting from.
All Rights Reserved.